| WDT: Tools Path Crawler | |||||||||||||||||||||||||||||||||||||||||
|
|||||||||||||||||||||||||||||||||||||||||
| Path Crawler | About Menu | Organizational Menu | University Menu | File Icons | Files | | |||||||||||||||||||||||||||||||||||||||||
| Description
The Path Crawler is required for Departments, Faculties, and Administrative pages. The Path Crawler is a hierarchical listing of a web page path. It starts by listing the root category of the page which most times will be the actual office or department, in other cases uprm.edu will be the root category. It continues by listing each sub category until it reaches the page. It will list a descriptive name. Each item in the list is a link to that category. Implementation A web page author can develop his own path crawler by following the guidelines above. The WDT has developed an online tool to automatically create a path crawler into any web page regardless of where it is hosted. This tools works by adding a Javascript into your pages that calls the crawler tool. The crawler tool is a PHP CGI that is available at http://www.uprm.edu/app/crawler.php. Getting Ready: Each director in the path must have a file named "crawler.txt". This file is used to retrieve the information printed for that directory. You can create this file in any text editor. The format for the crawler.txt is very simple. You must have one field per line. A field has the following format field name=field value. The first field is author. The field "author" is the email of the person in charge of the contents of that directory. The field "titlesp", which is the name in Spanish users will see in the path crawler. The field "titleen" is the same as "titlesp" but in English. The same way we have "linken" and "linksp" where you set the URL (the actual link) that the user will be taken when he or she clicks on that item. Fields can be in any order. If your pages only use one language you can use only those fields for the language you use. Example of a "crawler.txt" file:
You only put a crawler.txt file in folders which contain pages that use the path crawler tool. You must set the privilege for the crawler.txt so that the crawler tool can read the file. In a Unix or MacOS X system you can do this by using the chmod command in a Telnet or SSH session. Some web publishing tools and FTP applications provide a dialog to change a file privileges. |
|||||||||||||||||||||||||||||||||||||||||
|
Using the crawler tool in your pages: The crawler is placed in either the right or left side of your page right after the banner. To include a path crawler in a web page you must add one Javascript to your page. This java script is the one that calls the pathcrawler tool and generates the menu. The actual code for the java script is not included instead you call an external script. When you call the external script you must provide some arguments to the crawler tool so it can create your path.
The crawler tool requires two arguments to be able to create the Path Crawler: crawler.php?lang=sp&root=/news/index.html
The crawler tool also provides optional arguments that allow to fine tune the path crawler:
|
|||||||||||||||||||||||||||||||||||||||||
| Last Revision: Nov. 02, WDT, wmaster@uprm.edu |
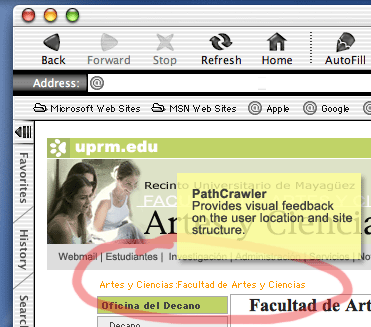 The Path Crawler is an interface element that allows users to easily navigate a site. It provides a quick feedback on the user location and overall structure of the site and possible link options within a site.
The Path Crawler is an interface element that allows users to easily navigate a site. It provides a quick feedback on the user location and overall structure of the site and possible link options within a site.